Personas SQL Traits
SQL Traits allow you to import user or account traits from your data warehouse back into Personas to build audiences, or to enhance Segment data that you send to other destinations.
SQL Traits are only limited by what data you have in your warehouse. Anything you can write a query for can become a SQL Trait, which allows you to add more details to your user and account profiles, which allows better and more nuanced personalization.
This unlocks some interesting possibilities to help you meet your business goals.
- Imagine you want to increase the CSAT (customer satisfaction score) of your Support team. You could create a SQL Trait of most common ticket requests for a customers’ industry by joining data from cloud sources like Zendesk and Salesforce, so you can better anticipate the user’s problems and speed up their solution.
- If you wanted to determine if a user is a resident of a specific area, you could query address data in your Warehouse and send this information as a true or false trait to a Personas audience.
- If you wanted to fill gaps in your customer profiles to include information from before you implemented Segment, you could import historical traits from your warehouse to fill in the gaps.
- If you wanted to more accurately predict lifetime value (LTV) for a customer, you can generate a complex query based on demographic and customer data in your warehouse, and use that information in a Personas audience to send personalized offers or recommend specific products.
- You could use similarly complex queries to build churn or product adoption models that cannot be easily calculated using Personas Computed Traits, and use them to inform your outreach efforts.
Check out our blog post for more customer case studies.
Example: Cloud Sources Sync
SQL traits allow you to import data from object cloud sources such as Salesforce, Stripe, Zendesk, Hubspot, Marketo, Intercom and more. For example, you could bring in Salesforce Leads or Accounts, syncing Zendesk ticket behavior, or Stripe LTV calculations.
The two examples below show SQL queries you could use to get cloud-source information from your warehouse.
Salesforce lead import If you wanted to import data from the Salesforce leads and contacts table, you could use SQL similar to the following query:
select external_id_c as user_id,
lead_score_c,
lead_age_c,
lead_status
-- …more properties
from salesforce.leads
Has Open Ticket in Zendesk
This query computes whether a user has an open ticket.
select distinct u.external_id as user_id, true as has_open_ticket
from zendesk.tickets t
join zendesk.users u
on u.id = t.requester_id
where t.status in ('pending','open','hold','new')
Setting up SQL traits
To use SQL traits you need:
- a Warehouse connected to Segment
- a Personas-enabled Segment workspace
- a user account with access to Personas in that workspace
Step 1. Set up a warehouse source
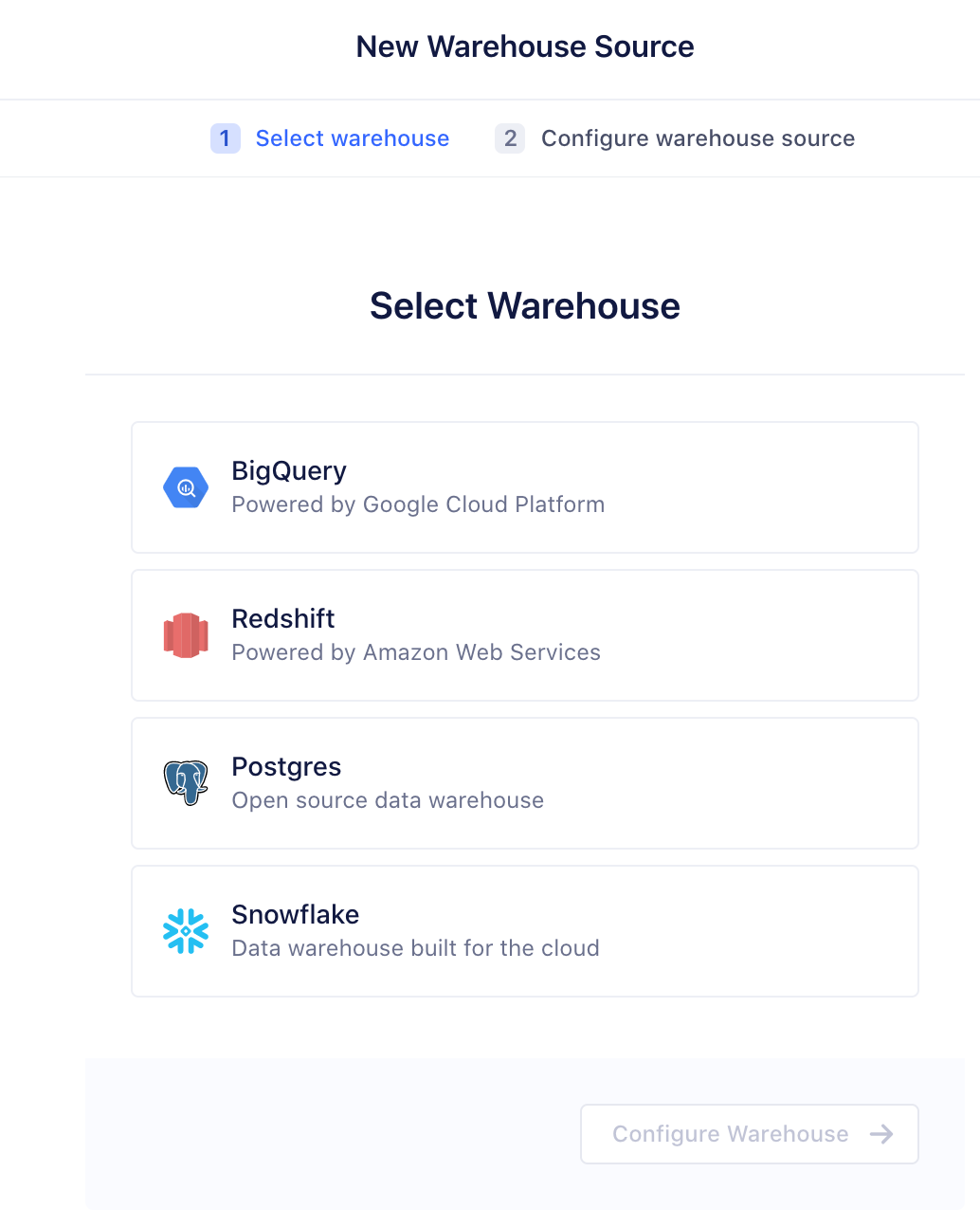
We currently support Redshift, Postgres, Snowflake, and BigQuery as data warehouse sources for SQL traits. The set up process for BigQuery is a bit different as it requires a service user.
For any warehouse, we recommend that you create a separate read-only user for building SQL traits.
Redshift, Postgres, Snowflake Setup
If you don’t already have a data warehouse, follow one of the guides here first:
Remember to create a read-only service user!
BigQuery Setup
To connect BigQuery to Segment SQL Traits, you must create a service account for Segment to use.
-
Navigate to the Google Developers Console.
-
Click the drop down to the left of the search bar and select the project to which you want to connect.

Note: If you don’t see the project you want in the menu, click the account switcher in the upper right corner, and check that you’re logged in to the right Google account for the project.
-
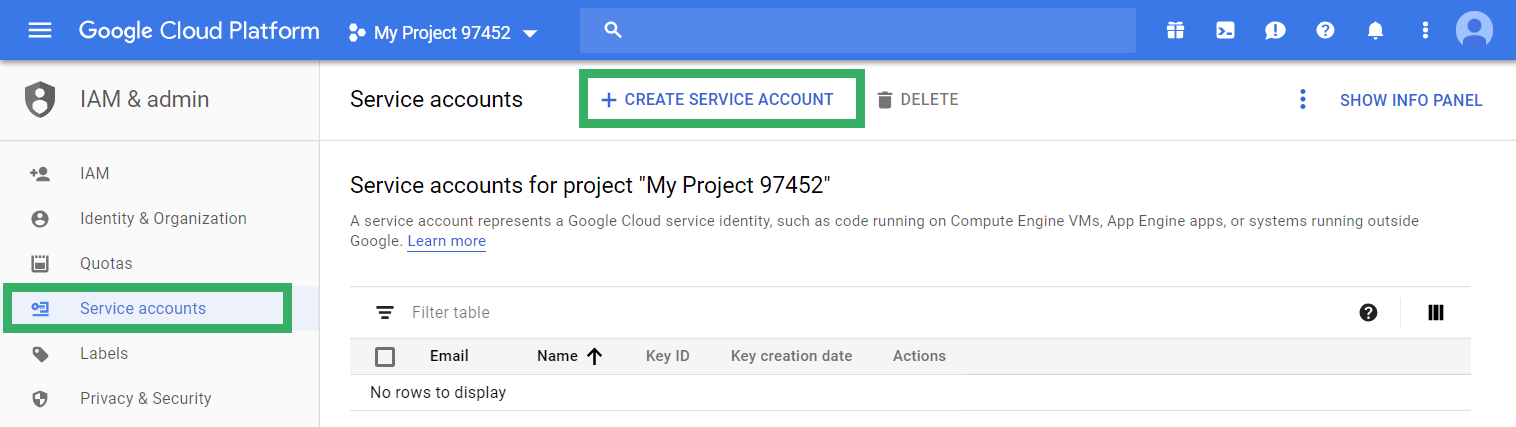
Click the menu in the upper left and select IAM & Admin, then Service accounts.
-
Click Create service account.
-
Give the service account a name - we recommend something like
segment-sqltraits. -
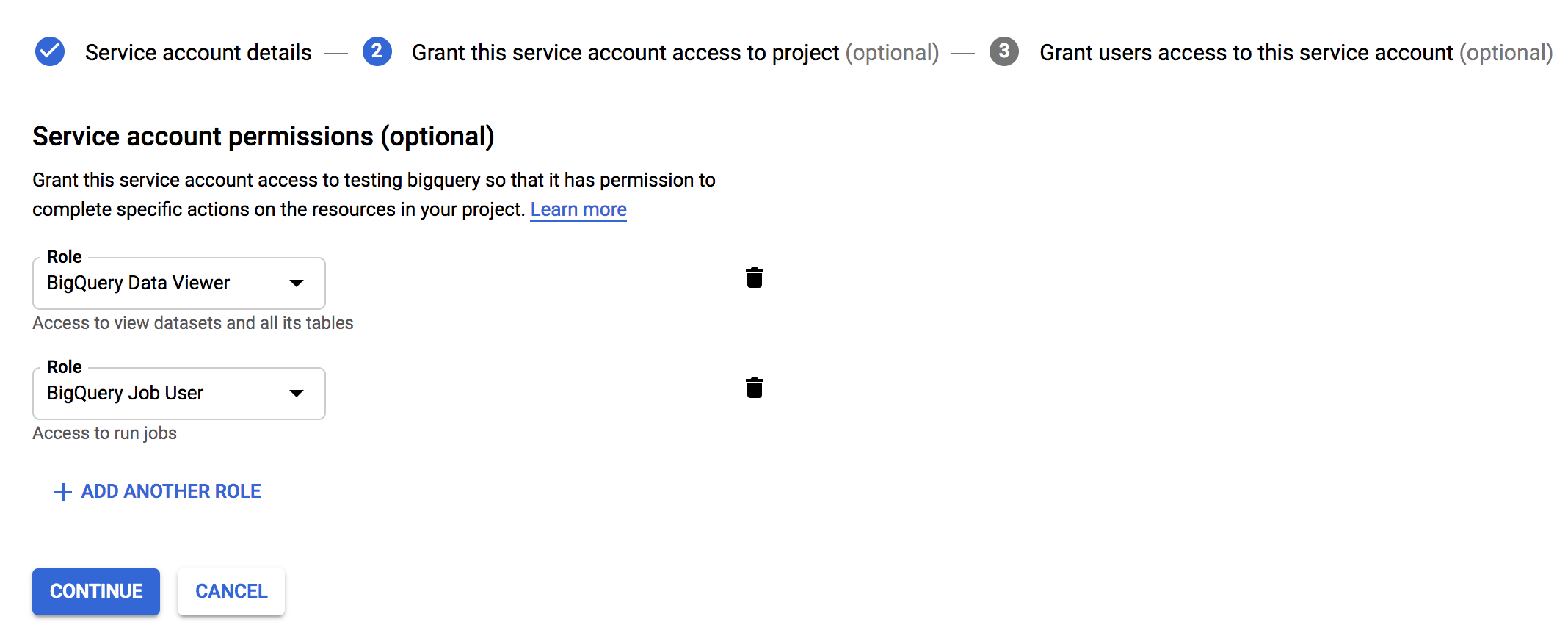
Under Project Role, add only the
BigQuery Data ViewerandBigQuery Job Userroles.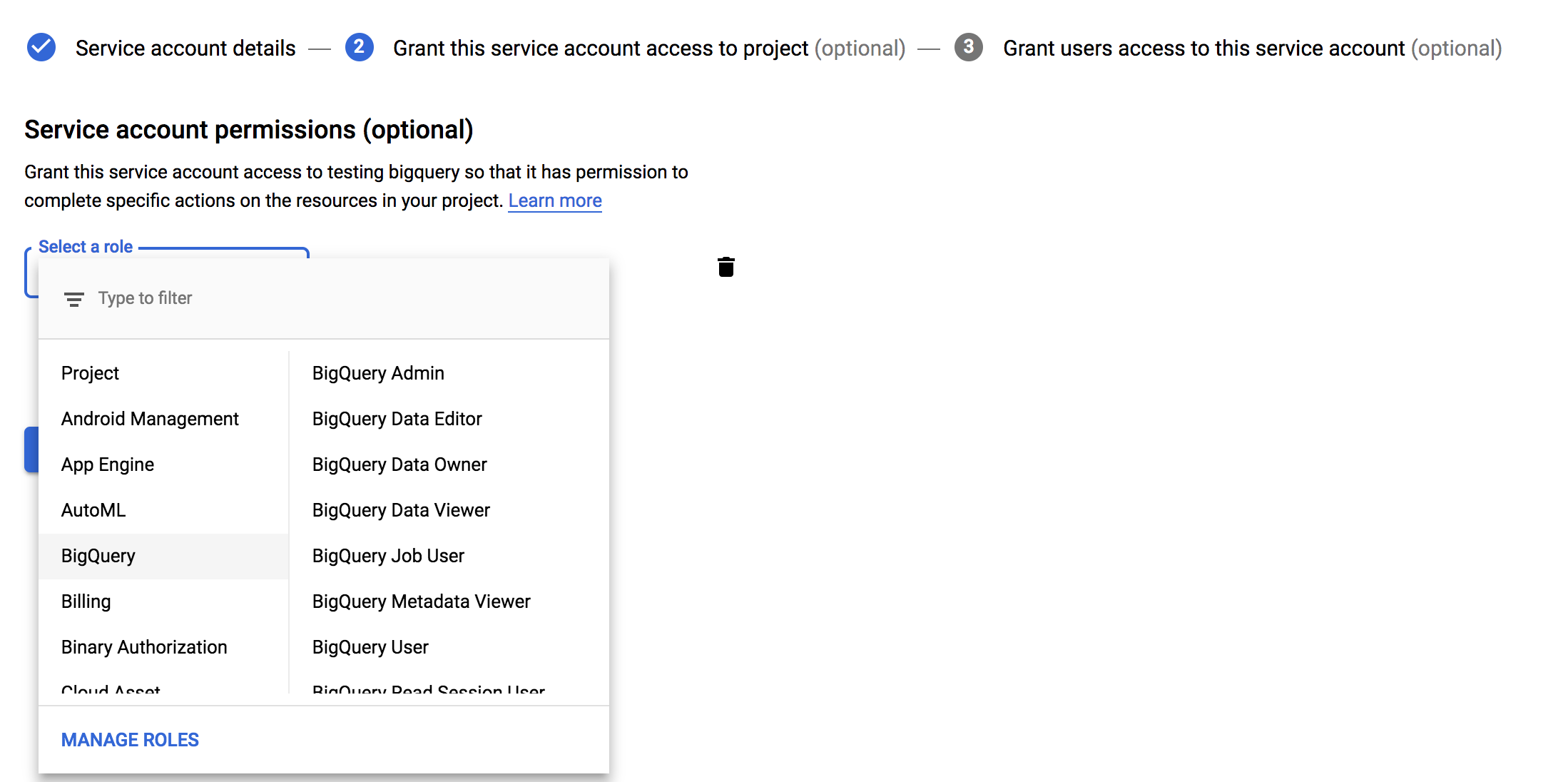
IMPORTANT: Do not add any other roles to the service account. Adding other roles can prevent Segment from connecting to the account.
-
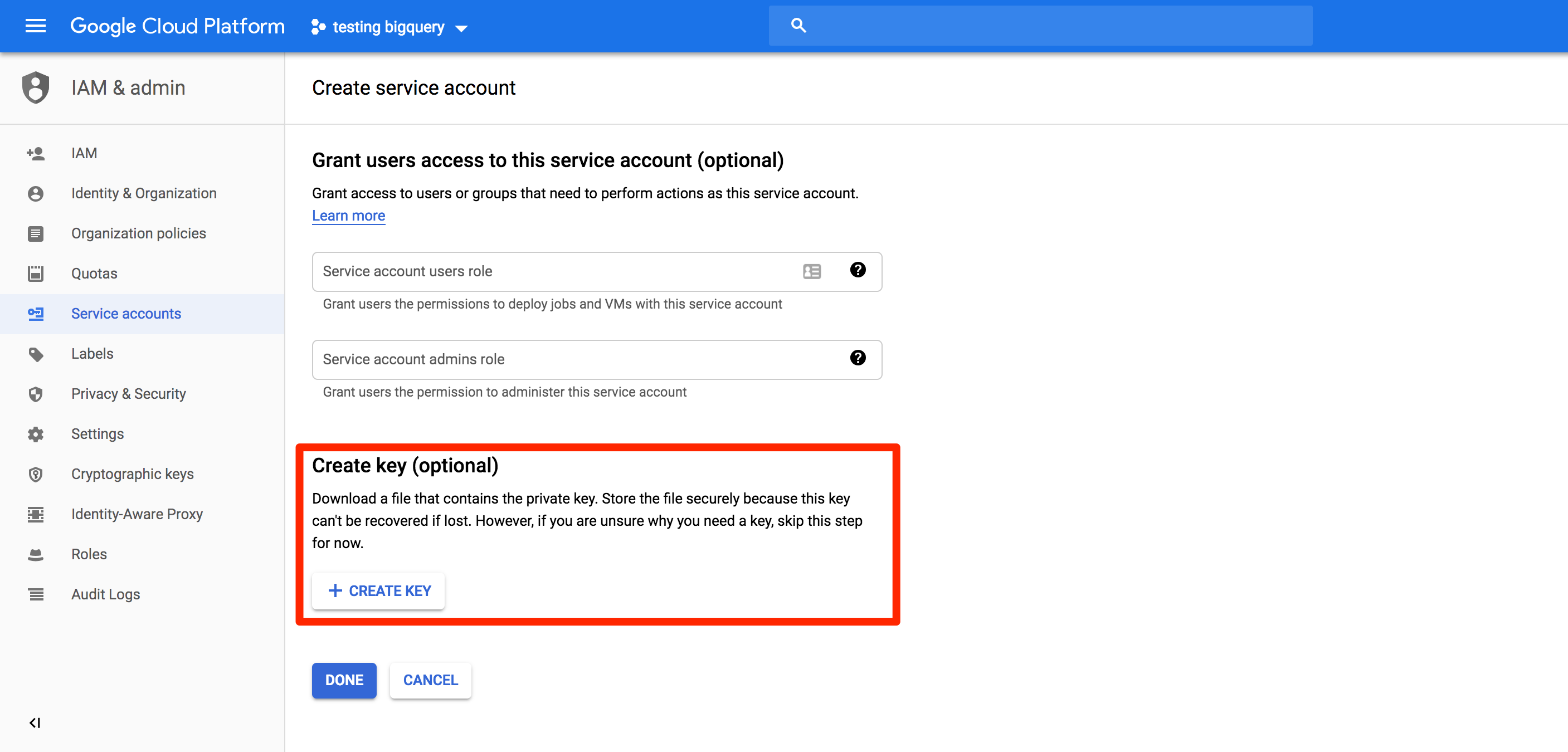
Click Create Key.
-
Select
JSONand click Create.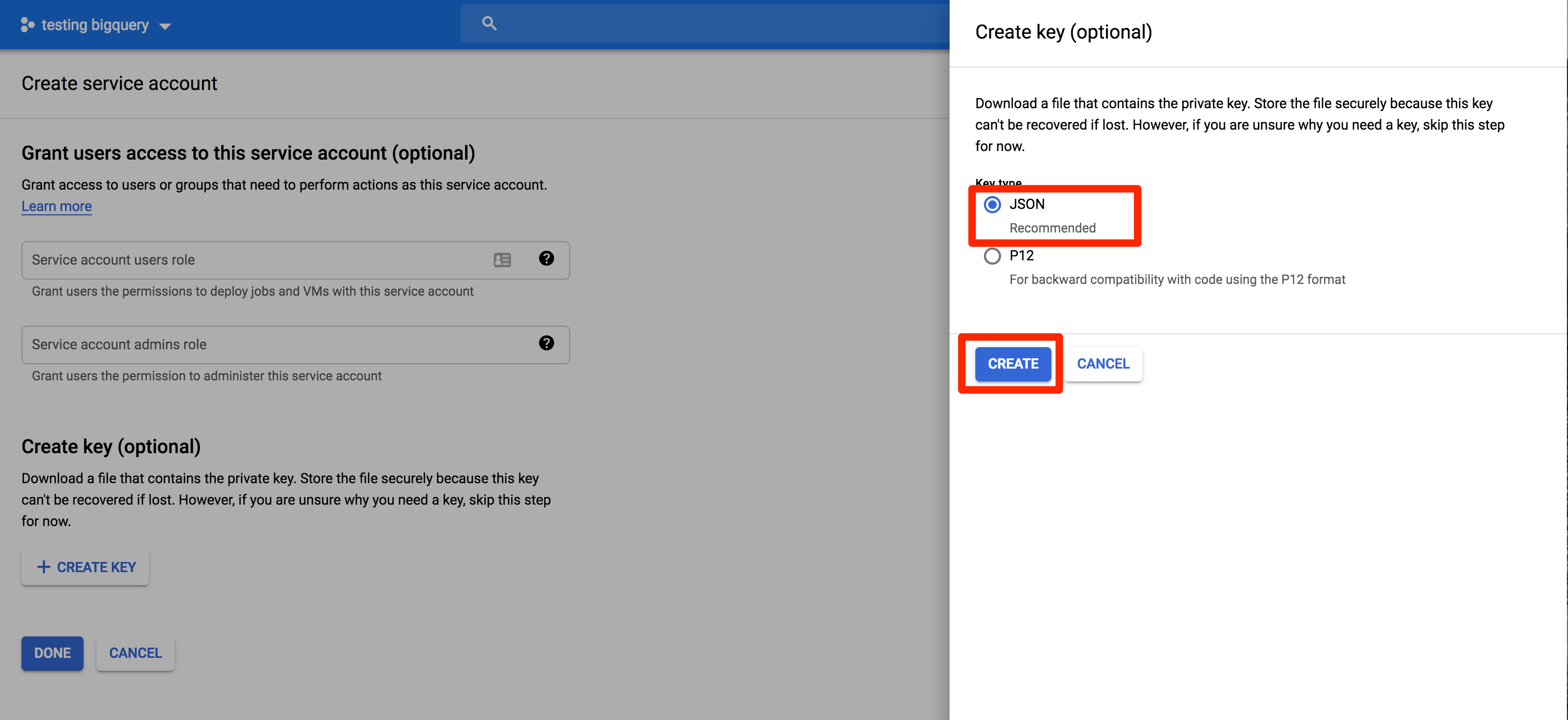
A file with the key is saved to your computer. Save this, because you’ll need it to set up the Warehouse source in the next step.
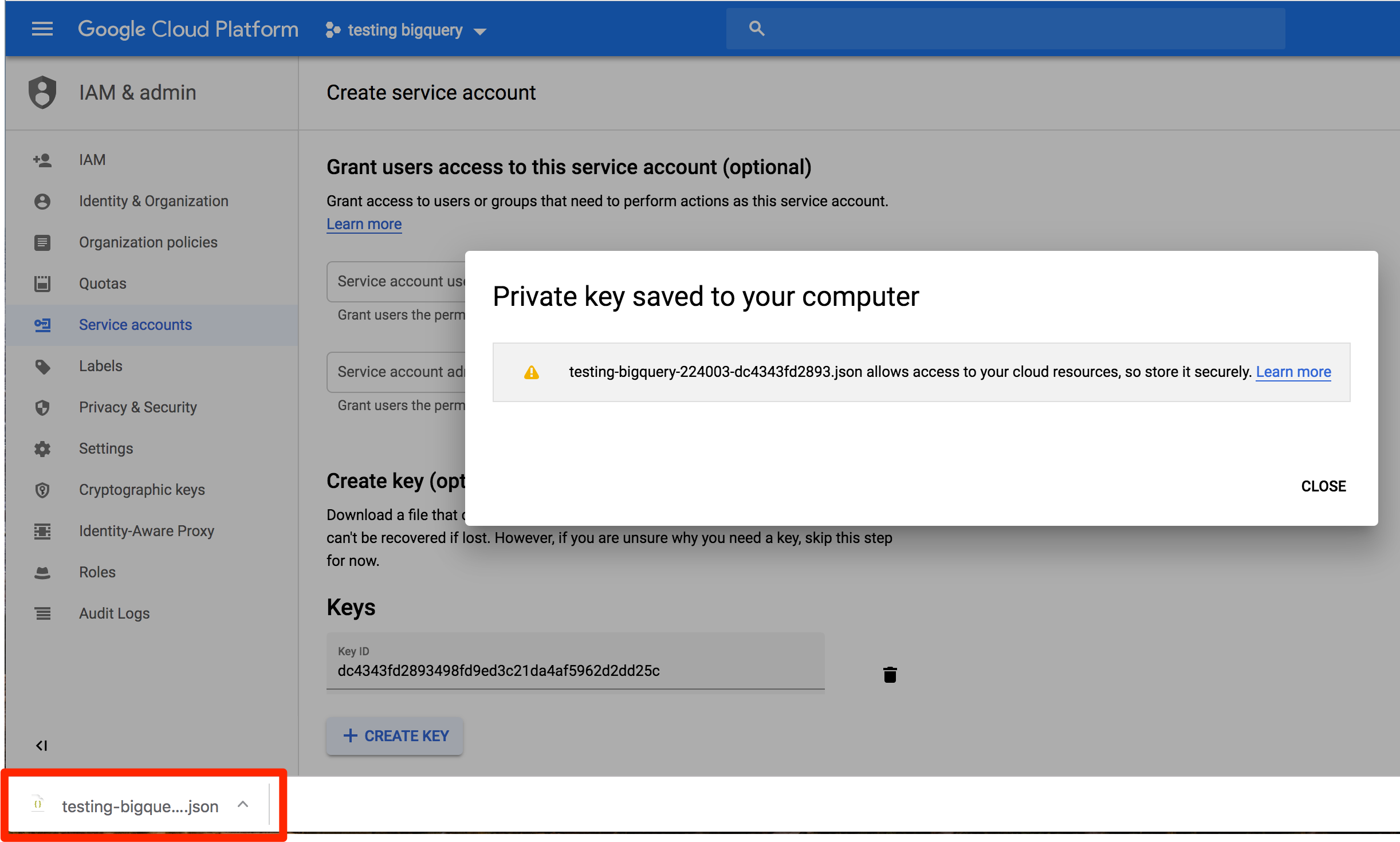
- Create new BigQuery Warehouse Source in Personas
Now you can create a new BigQuery warehouse source, upload the JSON key you just downloaded, and complete the BigQuery setup
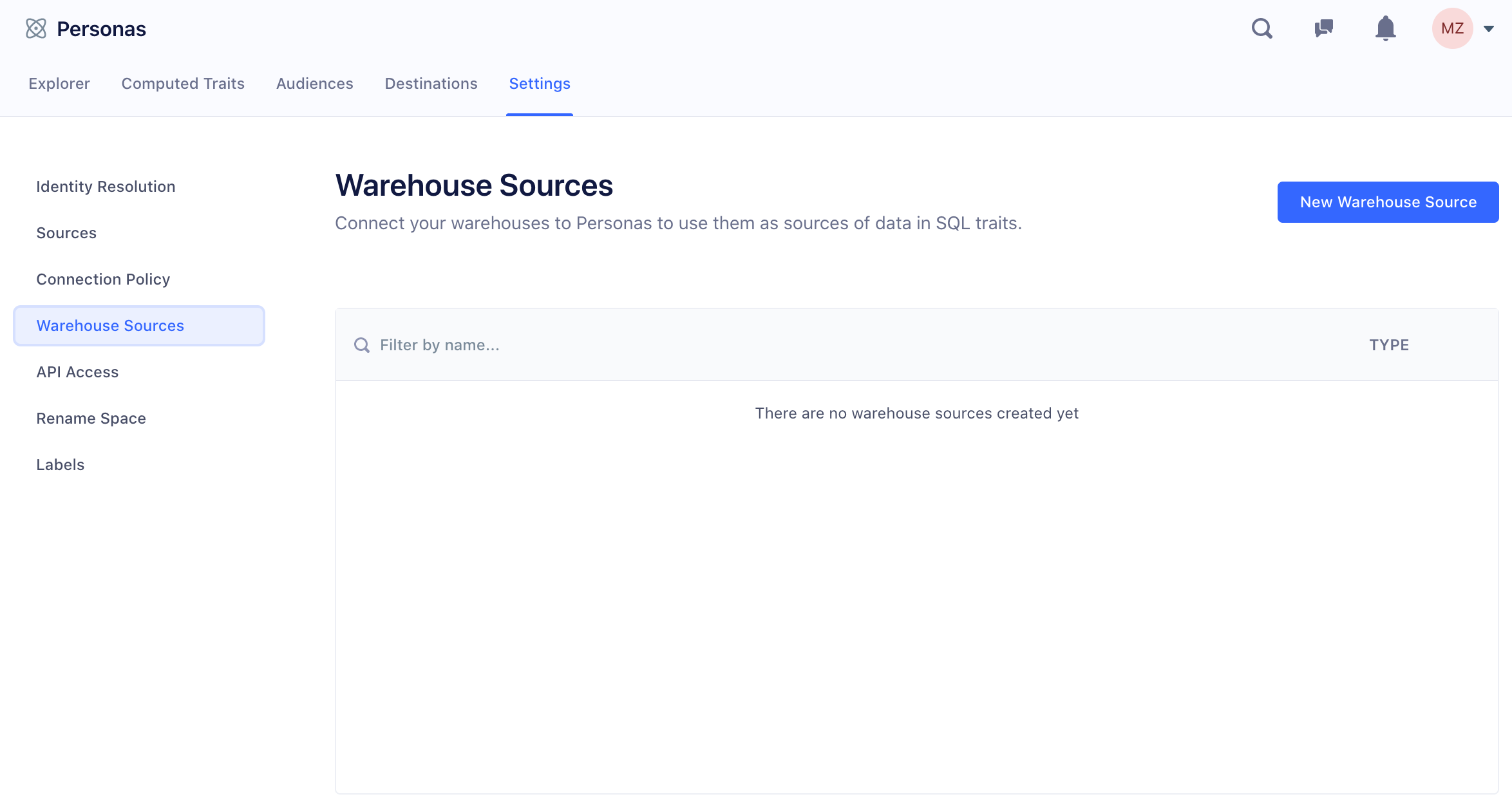
Step 2. Add the warehouse as a Personas Source
Once your warehouse is up and running:
-
Navigate to the Personas settings (Personas > Settings tab > Warehouse Sources), and click New Warehouse Source.
-
Select the type of warehouse you’re connecting.
-
In the next screen, provide the connection credentials, and click Save.
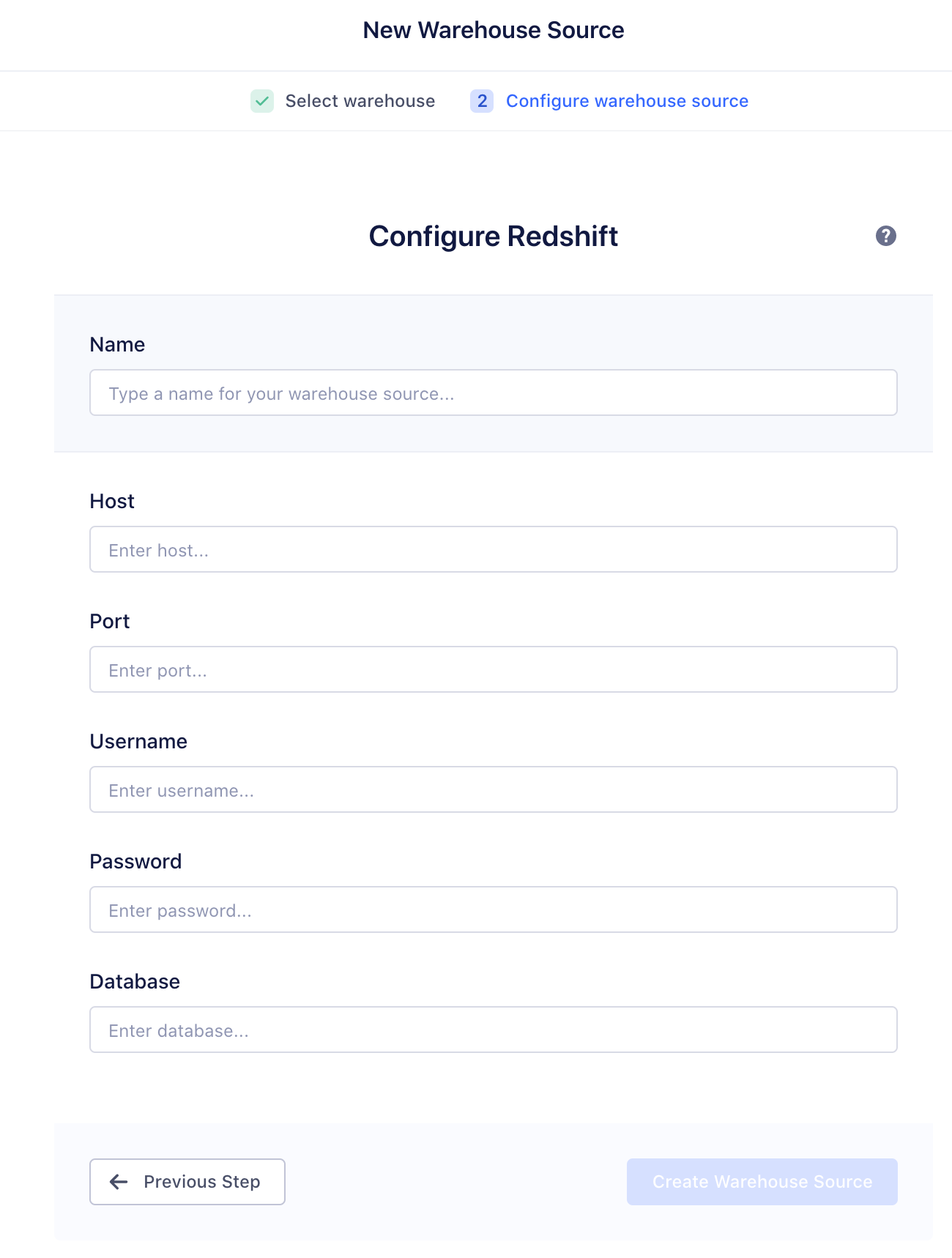
If you’re connecting a BigQuery warehouse, use the JSON key file that you downloaded as the last step.
Creating a SQL Trait
Before you create a SQL trait, you must first preview it to validate your query. If you’ve never used SQL before, we have a few templates you can use to try it out.
Preview the SQL trait
From the Personas screen, go to the Computed Traits tab, and click create a new SQL trait. Select the data warehouse that contains the data you want to query.
If you are sending data from object cloud sources to your warehouse, the SQL traits UI has some pre-made templates you can try out.
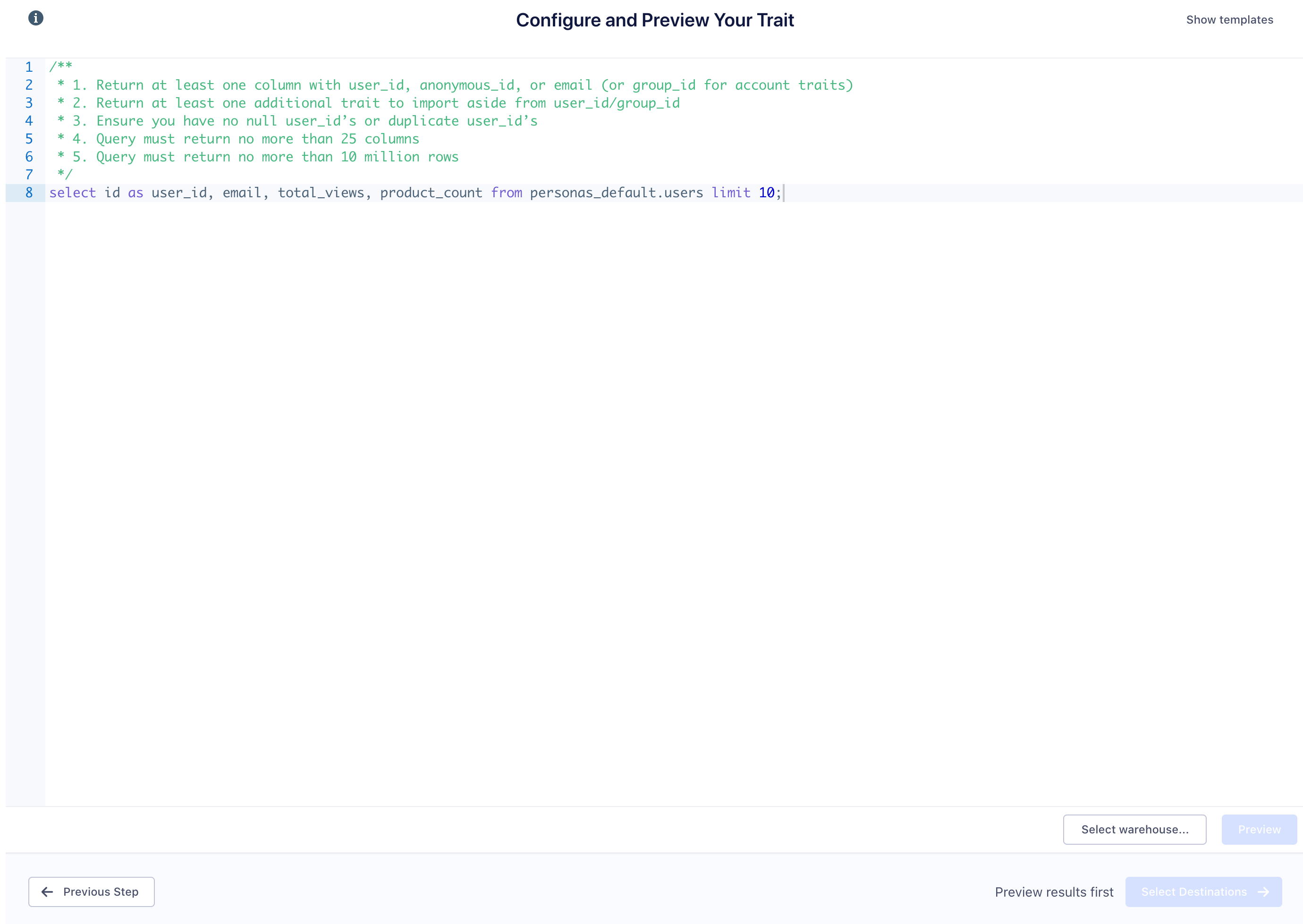
When you’re building your query, there are some requirements for the data your query returns.
- The query must return a column with a
user_id,email, oranonymous_id(orgroup_idfor account traits, if you have Personas for B2B enabled). - It must return at least one additional trait in addition to
user_id/group_id, and no more than 25 total columns - The query must not return any
user_ids with anullvalue, or any duplicateuser_ids. - The query must not return more than 10 million rows.
- Each record must be less than 16kb in size to adhere to Segment’s maximum request size.
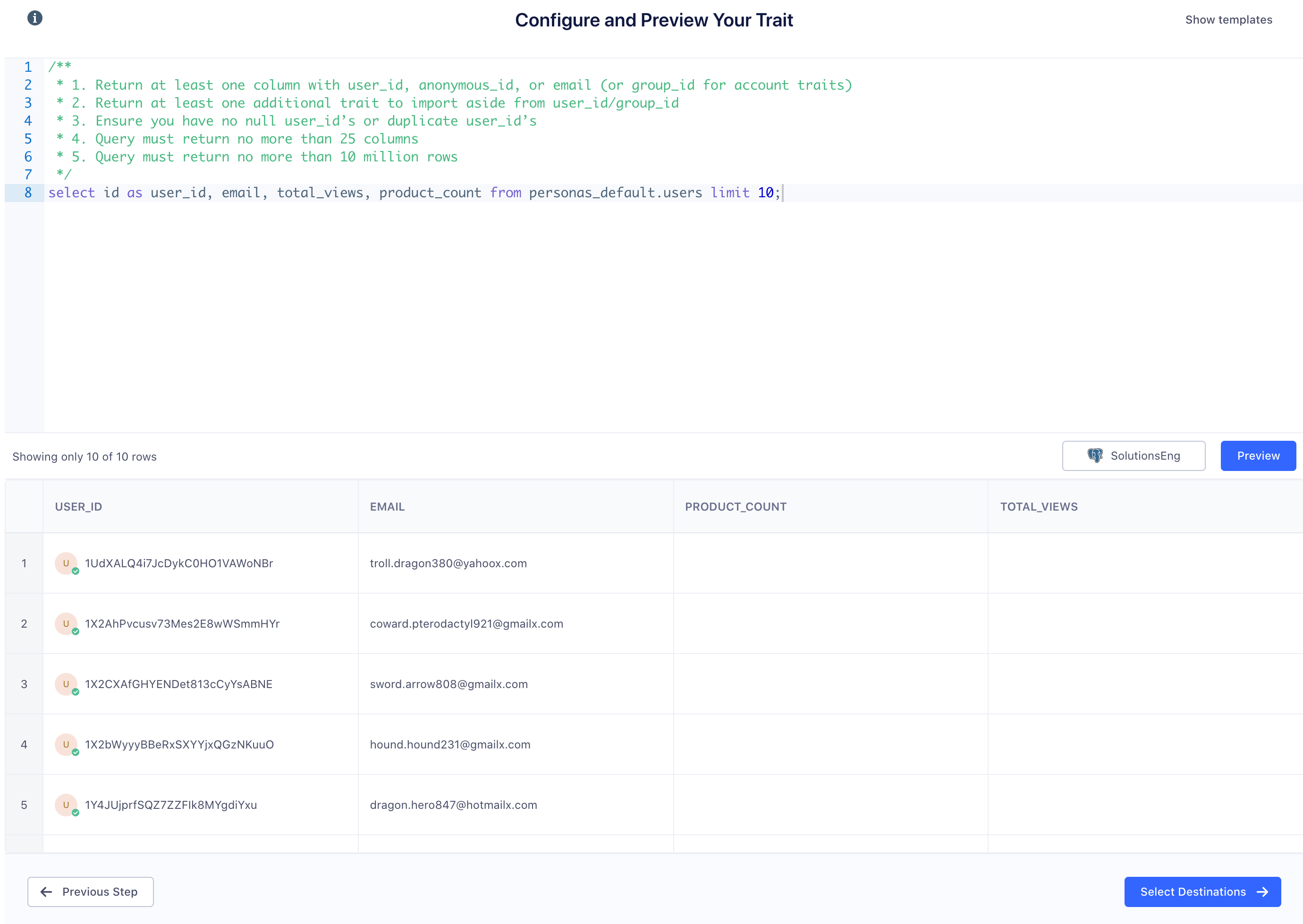
A successful preview returns a sample of users and their traits.
If we have seen a user before in Personas, their profile shows a green checkmark. You can click that user to view their user profile. If a user has a question mark, we haven’t seen this user_id in Personas before.
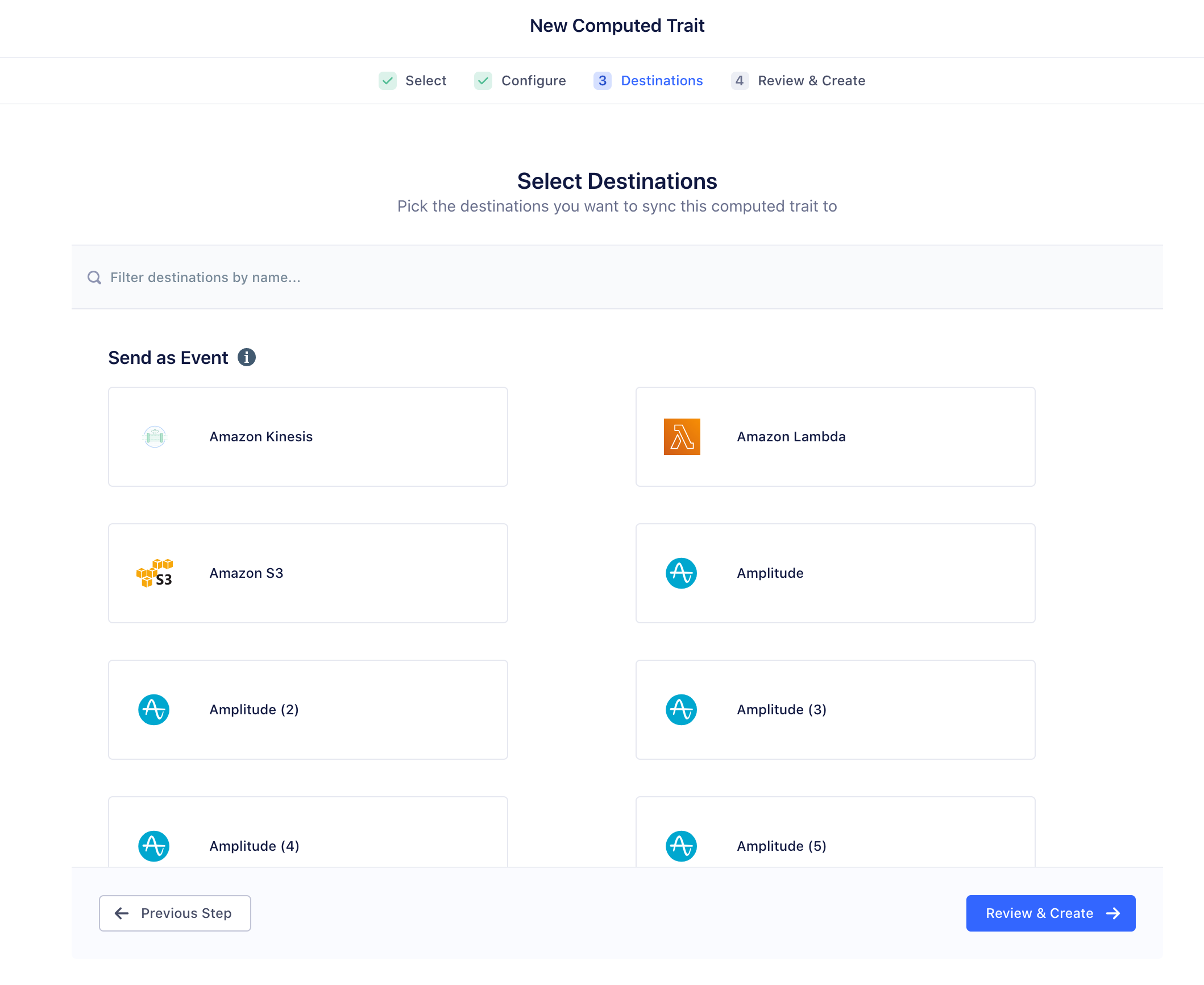
Configure SQL Trait options
Once you’re ready to import the SQL trait, select the destinations that you want to send this data to, or if you want to build Personas audiences from this data, you don’t need to select destinations, and can just click Skip.
Give your SQL trait a name. This is used as a label only, for descriptive purposes. If you’re importing multiple traits, give it a name like “Zendesk traits”. The trait names you use in audience-building or in your downstream tools correspond to the column names from the query.
If you’re building Personas audiences from this data, select “Compute without enabled destinations”.
Click Create Computed Trait to save the trait.
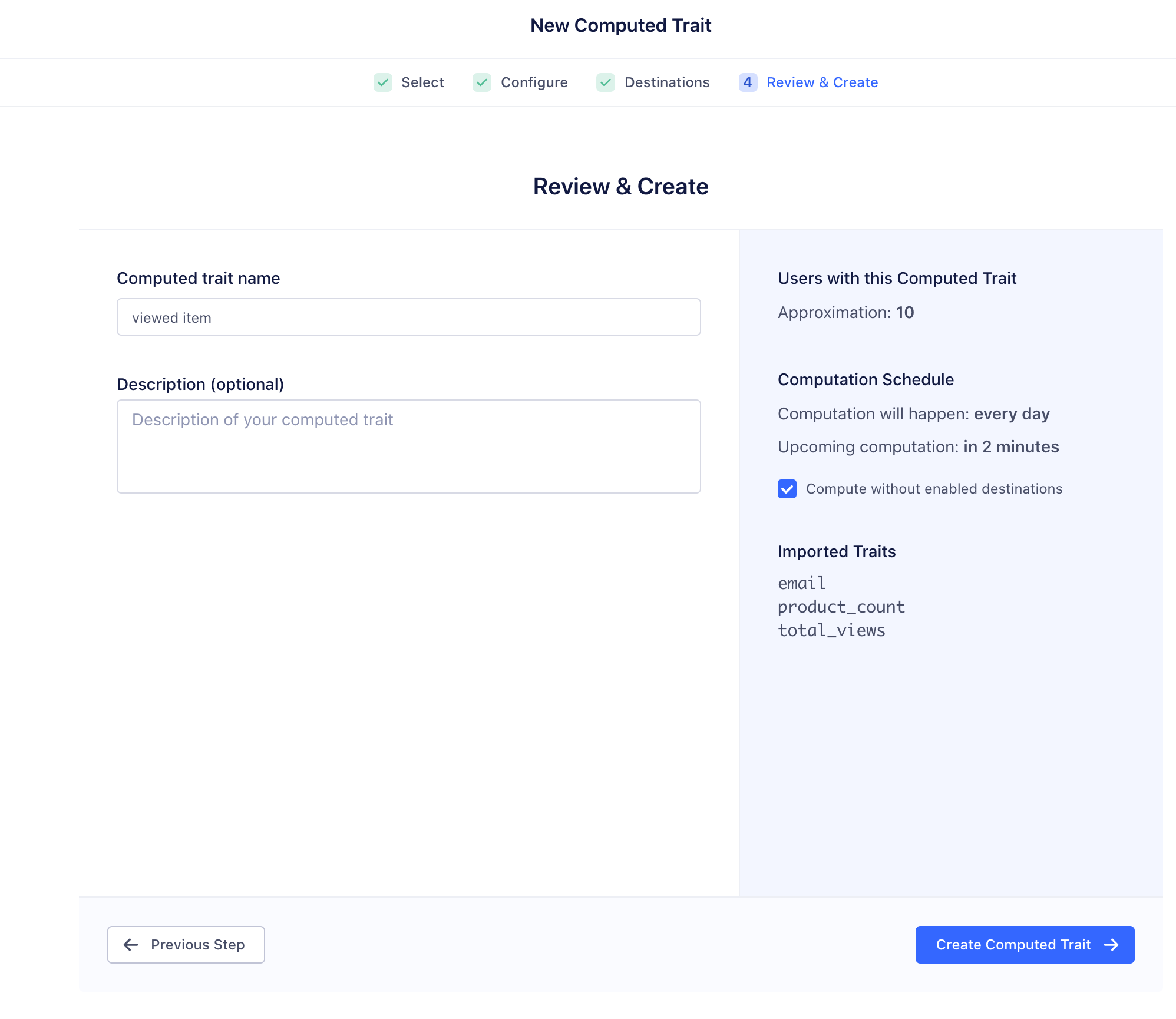 Check Compute without destinations if you only want to send to Personas
Check Compute without destinations if you only want to send to Personas
When you create a SQL trait, Segment runs the query on the warehouse twice a day by default. (If you’re interested in a more frequent or customizable schedule, contact us.)
For each row (user or account) in the query result, Personas sends an identify or group call with all the columns that were returned as traits. For example, if you write a query that returns user_id,has_open_ticket, num_tickets_90_days, avg_zendesk_rating_90days we send an identify call with the following payload:
{
type: 'identify',
userId: 'u123',
traits: {
has_open_ticket: true,
num_tickets_90_days: 3,
avg_zendesk_rating_90_days: 8
}
}
Happy Querying!
FAQs
Is there a limit to the result set that can be queried and imported?
The result set is capped at 10 million rows.
How often are you querying the customer’s data warehouse?
We query the data warehouse every 12 hours by default, but can query up to hourly. contact us if you need more customizable schedules.
What identifiers can I use to query a list?
You can currently query based on email, user_id or anonymous_id. If we don’t locate a match based on the chosen identifier, a new user profile is created. See question below.
Can you use SQL traits to create users in Segment? Or do SQL traits only append traits to existing users?
Yes, the Personas engine sends an identify call if there is no match between the identifier you chose and existing record. When this happens, Segment creates a new user profile. (This identify call happens in the back-end, and doesn’t show up in your Debugger.)
Does Personas send identify/group calls on every run?
No, Personas only sends an identify/group call if the values in a row have changed from previous runs.
I have a large (1M+) query of users to import, should I be worried?
If you’re importing a large list of users and traits, the biggest consideration is the API call usage and volume among the partners you are sending the data to. These vary depending on our partners, so contact us if you are concerned about this.
Is there a limit on the size of a SQL Trait’s payload?
Yes, Segment limits request sizes to a maximum of 16kb. Records larger than this are discarded.
Troubleshooting
I am getting a permissions error.
You might encounter a similar permissions error:

This is usually because you are querying a schema and table that the current user does not have access to. To check the table privileges for a specific grantee (user), go to your warehouse source credentials in Personas to retrieve the user name. Typically to grant access to a table, an admin needs to grant access to both a schema and table through the following similar commands:
GRANT USAGE ON SCHEMA ecommerce TO segment_user;
GRANT SELECT ON TABLE ecommerce.users TO segment_user;
Learn more about granting permissions:
- https://www.postgresql.org/docs/9.0/sql-grant.html
- https://stackoverflow.com/questions/17338621/what-grant-usage-on-schema-exactly-do
I am seeing a maximum columns error.

We currently support returning only 25 columns. Contact us with a description of your use case if you need to access more.
I am seeing a duplicate user_id error.
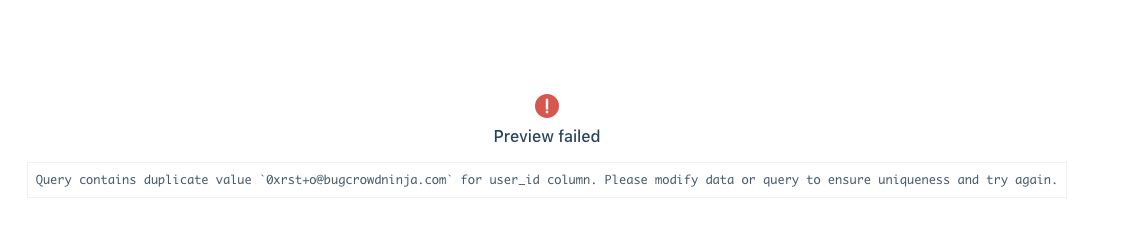
We require that each row of the query corresponds to a unique user. We throw this error if we see multiple rows with the same user_id. Use a distinct or group by statement to ensure that each row has a unique user_id.
I am seeing some users/accounts in my preview with questions marks. What does that mean?
This could mean one of two things:
1. We haven’t seen this user_id/group_id before in Personas
This means for the sources connected to Personas we have not received any event (identify, track, page etc) with this user_id. This could still be a legitimate user_id for a number of reasons, but before syncing, make sure you rule out option 2 (below) as sending a different identifier as the user_id can corrupt your identity graph.
2. You have the wrong user_id column
You might be returning a value for user_id that is inconsistent with how you track user_id elsewhere. We’ve seen cases where some customers want to return email as the user_id, or a partner’s tool id as the user_id. These are against our best practices and corrupt the identity graph if you are then tracking user_id differently elsewhere in your apps.
If you see only question marks in the preview, and have already tracked data historically with Segment, then you probably just have the wrong column. If you cloud source doesn’t have the database user_id, we recommend JOINing with an internal users table before sending the results back to Segment.
This page was last modified: 05 Mar 2021
Need support?
Questions? Problems? Need more info? Contact us, and we can help!